

Đôi Chút Về Vụ OpenAI Sa Thải Sam Altman
Đôi Chút Về Vụ OpenAI Sa Thải Sam Altman

OpenAI (ChatGPT, DALL-E…) được thành lập năm 2015 bởi Elon Musk, Sam Altman (Co-founder của YC), Greg Brockman (CTO cũ của Stripe), IIya Sutskever (chuyên gia hàng đầu về ML) cùng nhiều chuyên gia khác. OpenAI Inc, được thành lập dưới dạng tổ chức phi lợi nhuận và vẫn là tổ chức phi lợi nhuận cho đến nay.
Elon Musk từng chia sẻ mục tiêu ban đầu của OpenAI được lập ra để giúp việc phát triển AI an toàn hơn bơi vì tổ chức sẽ không chịu ảnh hưởng của áp lực tăng trưởng về lợi nhuận cũng như thương mại hóa công nghệ khi nó chưa đủ an toàn. Tầm nhìn xa hơn là trở thành một tổ chức nghiên cứu hàng đầu cung cấp model AI nguồn mở (open-source AI) để công nghệ này có thể được phân chia đều cho tất cả mọi người trong xã hội, tránh trường hợp một nhóm tổ chức hoặc đất nước độc quyền công nghệ này và việc này rất nguy hiểm với nền văn minh loài người.
Đây cũng là lí do Elon Musk (chưa rõ tự nguyện hay bị bắt buộc) rời khỏi board của OpenAI vào 2018 để tránh conflict of interest với Tesla (vì Tesla cũng phải tập trung phát triển AI rất mạnh cho công nghệ xe tự lái), và Tesla là một công ty tư nhân for-profit.
Tuy nhiên vào 2019 thì tổ chức thành lập thêm 1 công ty con thuộc sổ của OpenAI Inc là OpenAI LP (capped-profit), cho phép nhà đầu tư được lãi tối đa 100 lần. Cấu trúc này tổ chức này cho phép OpenAI đi gọi vốn từ các quỹ đầu tư VC và các tập đoàn lớn. Elon Musk cho rằng việc mở một nhánh for-profit cho tổ chức gần như phá hỏng đi hoàn toàn sứ mệnh ban đầu của OpenAI nên đã rất nhiều lần công khai công khích CEO hiện tại của OpenAI là Sam Altman về vấn đề này, thậm chí đợt vừa rồi vẫn reply rất troll trên X trong vụ việc vừa qua của Sam.
Để bảo vệ cho hành động của mình thì Sam cũng có chia sẻ trên Lex Fridman podcast rằng việc structure công ty như vậy giúp cho OpenAI tăng tính linh động của tổ chức trong những trường hợp yêu cầu vốn đầu tư lớn (để phát triển data warehouse cũng như phần cứng để train models). “Văn” của SamA là cấu trúc hiện tại hoàn hảo bởi vì vẫn được theo dõi và giám sát bởi board của tổ chức non-profit trong khi cấu trúc for-profit cho phép OpenAI chạy đua hết tốc lực với các đối thủ khác trên thị trường. Cái này cũng có cái lí đúng của nó, mình sẽ giải thích technical hơn ở phần dưới.
Board của Open AI Inc. (tổ chức mẹ phi lợi nhuận) bao gồm 6 người, 3 người thuộc OpenAI bao gồm **Ilya Sutskever (**Giám đốc khoa học của OpenAI), Greg Brockman và Sam Altman. Ngoài ra thì có có 3 người khác không thuộc biên chế của OpenAI: Adam D’Angelo, Tasha McCauley, Helen Toner. Những người này có background về khoa học, nghiên cứu hoặc khởi nghiệp về công nghệ.
(Mọi người có thể google hoặc hỏi ChatGPT để biết rõ hơn về background của những người này.)
Bởi vì OpenAI là tổ chức phi lợi nhuận nên thực ra những người nằm trong board không yêu cầu phải có cổ phần của công ty. Ngay cả Sam Altman điều trần với Quốc Hội Mỹ cũng nó ông không sở hữu bất kì cổ phần nào của công ty (nhưng thực ra là fail to disclose là YC có sở hữu cổ phần của OpenAI LP, và Sam là Co-founder của YC nên vẫn có indirect ownership).
Nhiệm vụ của board ở OpenAI Inc. là đảm bảo OpenAI vẫn đi theo sứ mệnh được đề ra ban đầu theo hướng phi lợi nhuận. Mặt khác, OpenAI LP đang phát triển rất nhanh, liên tục ra những model mới và thậm chí là râm ran tin đồn về rất nhiều bước tiến vượt bậc trong nội bộ công ty (chẳng hạn như dự án Q* - sẽ nói rõ hơn ở phần cuối).
Tua nhanh đến tuần vừa rồi, trước khi Sam Altman bị sa thải và đồng thời cùng bị vote out ra khỏi Board cùng với Greg. Lí do giang hồ đồn đoán là vì Sam với Greg đang rất năng nổ (aggressive) đi gọi vốn cho OpenAI LP, đặc biệt là gọi vốn từ các quỹ VC. Tuy nhiên đến cuối ngày thì công việc của các nhà đầu tư VC là kiếm lãi từ khoản đầu tư của họ, vậy nên việc tạo áp lực thương mại hóa sớm sản phẩm là đều hiển nhiên.
Với mình thì đây là lí do chính mà board cùng với Ilya Sutskever đồng ý sẽ đẩy 2 người kia đi vì những lo ngại về tốc độ đẩy những sản phẩm chưa được cân nhắc kĩ về mức độ an toàn ra thương mại hóa quá nhanh. Chính vì OpenAI Inc là công ty mẹ của OpenAI LP, và board hiện tại của OpenAI Inc cũng chính là Board của OpenAI LP, vậy nên quyết định sút SamA và Greg không cần thông qua các nhà đầu tư vào OpenAI LP, cụ thể là Microsoft và các nhà đầu tư khác. Và như ý mình nêu ở trên, mình tin là board cũng có cái lí của riêng họ, với vị trí và trách nhiệm của họ với tổ chức phi lợi nhuận OpenAI Inc.
Thế nhưng đời không đơn giản như thế. Với áp lực dư luận cũng như từ nhân viên của công ty, người phải rời khỏi tổ chức sau cùng là board chứ không phải là SamA và Greg.
Với mình thì đây có thể là một bước ngoặt mới của OpenAI, khi vị thế, tiếng nói và quyền hành của SamA + Greg lớn hơn rất nhiều mặc cho board hiện tại có là ai. Tin tốt là SamA với Greg có thể tự do hơn phát triển và thương mại hóa rất nhiều sản phẩm của công ty. Tin xấu là AI safety và tiếng nói đối với những mối lo về AI safety cũng yếu hơn rất nhiều, thậm chí có thể đi lệch hẳn khỏi sứ mệnh ban đầu của tổ chức.
Tuy nhiên nói đi cũng phải nói lại, việc cần vốn để tiếp tục cạnh tranh với đối thủ ở thời điểm này là hoàn toàn có lí. Andrej Karpathy, từng là giám đốc AI và công nghệ tự lái của Tesla, vừa chia sẻ gần đây về một video giải ngố về LLM. Trong đó có một đoạn nói rằng riêng với AI thì tham số và lượng dữ liệu train càng lớn, thời gian train càng lâu thì model càng thông minh hơn the cấp số mũ, khả năng cao là “free from diminishing marginal growth” (cụm này chả biết dịch ra tiếng Việt như nào).
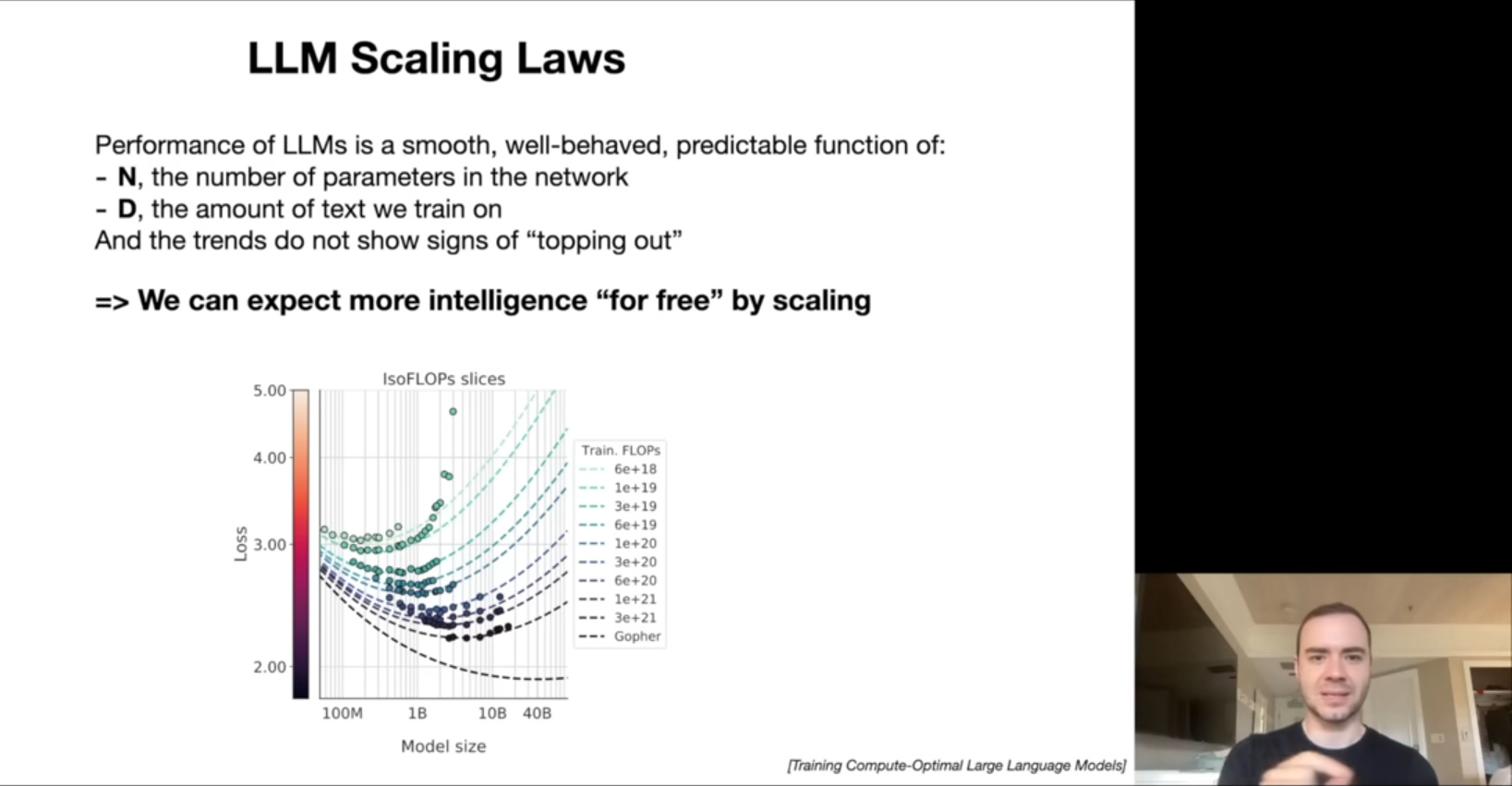
Điều đó có nghĩa là các công ty AI hiện tại đang cạnh tranh nhau dựa trên số độ lớn của tập dữ liệu cũng như phần cứng, data-warehouse…và những thứ này tốn rất nhiều tiền, vậy nên không có tiền thì không thể cạnh tranh lại kịp được và sẽ không sớm thì muộn mất vị thế market leader.
Còn Q* project, một dự án mà Ilya Sutskever từng chia sẻ rằng OpenAI đang phát triển trong nội bộ, với tiềm năng cho thấy được AI có thể bắt đầu tự giải được toán tiểu học. Nhiều người có thể sẽ thắc mắc tưởng rằng ChatGPT giờ giải được cả toán cao cấp, thì thực ra đó là học thuộc chứ không phải giải.
GPT models hiện tại là học thuộc lời giải từ những nguồn khác trên mạng hoặc từ những tập dữ liệu có sẵn, sau đó chọn ra đáp án tìm được có xác xuất đúng cao nhất, nên vẫn đang chỉ là ghi nhớ. Còn Q* là dự án hướng tới việc giúp cho AI có thể tự giải được toán thông qua model Tree-of-Thoughts, nghĩa là train cho model có khả năng reasoning thông qua recursive prompting technique, nghĩa là tạo ra hàng tá bước lập luận (reasoning) thay vì phải học thuộc đáp án trong các tập dữ liệu có sẵn dùng để train.
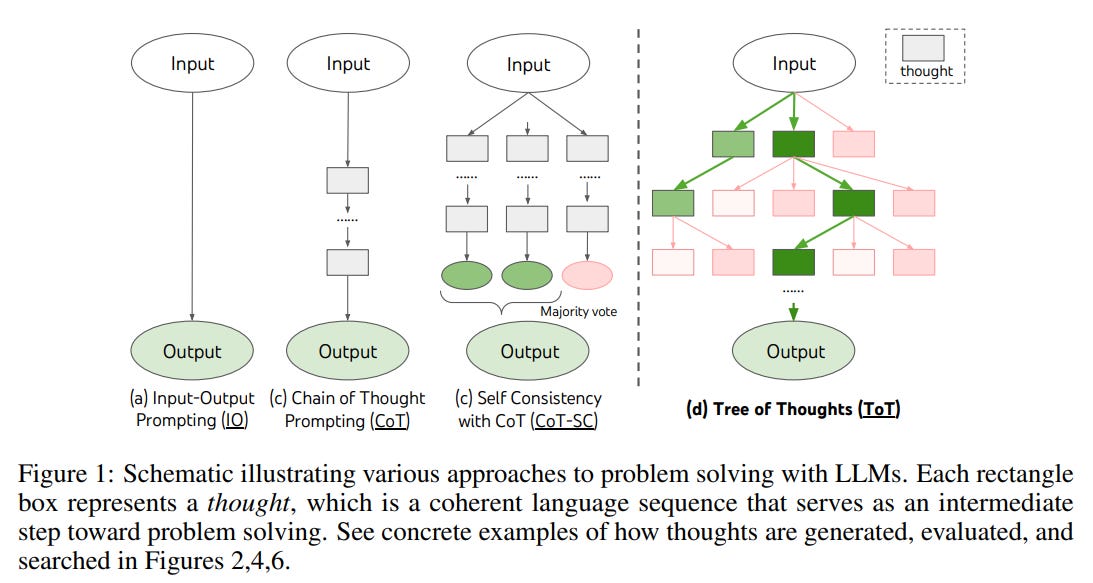
Có thể hiểu dễ hơn bằng ví dụ đơn giản trong việc giải toán. Ở model LLM hiện tại khi hỏi OpenAI một câu hỏi toán cấp 3, model hiện tại sẽ học thuộc hàng triệu đáp án trong tệp dữ liệu train ban đầu, sau đó trả lời câu hỏi đó nhiều lần. Mỗi lần đưa ra câu trả lời đó sẽ có con người chấm điểm, rồi cuối cùng model chọn ra câu trả lời có xác suất được chấm đúng cao nhất bày ra cho người dùng.
Còn AI có Tree-of-Thought hay khả năng reasoning như Q* (nếu thực sự developed thành công) thì sẽ giải bài toán cấp 3 đó bằng cách học hiểu và trả lời đúng tất cả những kiến thức toán từ cấp 1 đến cấp 3. Model này yêu cầu nhiều tài nguyên hơn để train vì như có thể thấy trên hình, phải liên tục sinh ra hàng triệu chuỗi lập luận khác nhau và chuỗi nào sai thì sẽ bị loại bỏ, lặp đi lặp lại cho tới khi tạo ra được những chuỗi lập luận (chain of reasoning) đúng với yêu cầu về đầu ra nhất.
Cũng chính vì vậy, nếu như con AI này thực sự được phát triển thành công đạt được cảnh giới cao nhất trong các môn khoa học, nó sẽ mở ra khả năng nghĩ ra những công thức mới, những quy luật toán, vật lí, khoa học mới mà các nhà khoa học hàng đầu vẫn đang tiếp tục nghiên cứu hàng ngày. Và một khi những công nghệ này có thể phá bỏ giới hạn về vật lí, sinh học, hóa học, toán học, thì sẽ nhiều hơn nữa những vũ khí được sinh ra (tương tự như cách dự án Manhattan tạo ra bom nguyên tử) và cũng có thể là lí do mà họ quyết định sa thải Sam Altman.
Mình dùng ChatGPT hàng ngày cho tới mức mình có thể claim rằng 100% deliveribles của mình dù cho công việc research hay data analysis đều đang dính tới LLM, vậy nên đúng ra mình nên có biased dành cho AI. Dẫu vậy, những lập luận hay quan ngại mà với nhiều người có thể là “fear-mongering” hay “muốn đè nén sự phát triển của AI”, với mình cũng rất đáng để cân nhắc.
Chí